nifi mergerecord는 schema가 동일한 여러 개의 flowfile을 하나로 병합해주는 프로세서로,
csv, json, avro format 모두에서 사용 가능하다.
header가 다르면 merge하지 못함.
여러가지 테스트 케이스를 통해 동작원리를 파악해보려고함
- generateflowfile1의 Custom Text
test1,test2,test3
a,b,c
- generateflowfile1의 Custom Text
test1,test2,test3
a1,b1,c1
- generateflowfile1의 Custom Text
test1,test2,test3
a2,b2,c2
- TEST CASE 1
mergerecord의 config를 default값으로 두고 generateflowfile1, 2, 3을 1초 간격으로 실행함.
결과) merge가 안되었음

- TEST CASE 2
Max Bin Age를 3 seconds으로 Max Bin Age을 1로 한 후 genereateflowfile 1, 2, 3을 1초 간격으로 실행함.
정상적으로 merge가 되지 않아서 Minimum Number of Records을 변경 후 다시 테스트를 진행하였음
MergeRecord의 Minimum Number of Records 값을 3으로 설정, Max Bin Age의 값을 3 seconds로 설정 후 generateflowfile 1, 2, 3을 1초 간격으로 실행한다. 정상적으로 merge가 진행되었다.
Max Bin Age를 3 seconds로 해도 Max Bin Age을 1로 하면 정상적으로 merge가 되지 않는 것을 확인하였음
결과) queue를 보면 정상적으로 merge가 된 것을 확인할 수 있다.
test1,test2,test3
a,b,c
a1,b1,c1
a2,b2,c2
- TEST CASE 3
generateflowfile 1의 Batch Size config를 2000으로 설정해 한번에 2000개의 file을 생성한다. Maximum Number of Records의 default가 1000이기에 flowfile이 2개로 merge될 것으로 예상함.
결과) 다음과 같이 2000개의 flowfile이 flowfile 하나당 1000 row씩 2개의 flowfile로 merge되었음
1 test1,test2,test3
2 a,b,c
3 a,b,c
4 a,b,c
5 a,b,c
.
.
.
999 a,b,c
1000 a,b,c
1001 a,b,c
- TEST CASE 3
Correlation Attribute Name을 사용해 Attribute가 같은 flowfile들끼리 merge하도록 함.
generateflowfile 1과 2에 updateattribute로 merge라는 attribute를 생성 후 A 값을 부여함
generateflowfile 3에는 updateattribute로 merge라는 attribute를 생성 후 B 값을 부여함
의도대로라면 generateflowfile 1, 2가 하나로 merge되고, 3은 merge되지 않고 다음 프로세서로 넘어가야함.
generateflowfile1, 2의 UpdateAttribute는 다음과 같이 설정함
| merge : A |
generateflowfile 3의 UpdateAttribute는 다음과 같이 설정함
| merge : B |
MergeRecord는 다음과 같이 설정함
| Correlation Attribute Name : merge Minimum Number of Records : 2000 Maximum Number of Records : 2000 Max Bin Age : 5 seconds |
주의 : Correlation Attribute Name은 ${merge}가 아닌 merge로 작성해야함.
결과) 의도대로 Attribute Name이 같은 1과 2가 merge되었음.
- TEST CASE 4
generateflowfile과 MergeRecord 사이의 connection Load Balance Strategy가 Round robin일 때와, Single node일 때의 차이를 비교해봄
generateflowfile은 다음과 같이 설정함 (Execution을 primary node가 아닌 all node로 설정하였음)
| Batch Size : 100 |
MergeRecord는 다음과 같이 설정함
| Minimum Number of Records : 400 Maximum Number of Records : 1000 Max Bin Age : 5 seconds |
- connection Load Balance Strategy가 Round robin일 때
MergeRecord의 In, Out을 보면 400개의 flowfile이 들어가 4개의 flowfile로 merge되어 나온 것을 볼 수 있다.
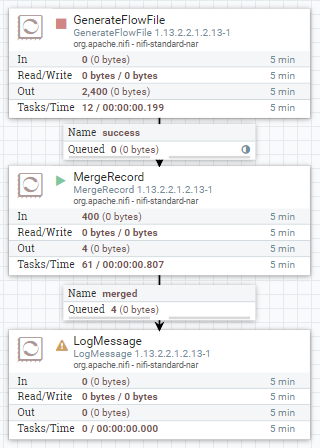
현재 test 중인 nifi cluster는 서버 4대로 구성되어 있음.
list queue로 node를 보면 4개의 flowfile이 각각 다른 node에서 생성되었음을 확인할 수 있다.
Round robin을 적용하면 queue가 서버 4대에 골고루 분산되기에 하나로 합쳐지지 않고 4개로 합쳐진 것으로 확인된다.

- connection Load Balance Strategy가 Single node일 때
connection Load Balance Strategy를 Single node 설정한 경우에는 하나의 flowfile로 잘 merge된 것을 확인할 수 있다.
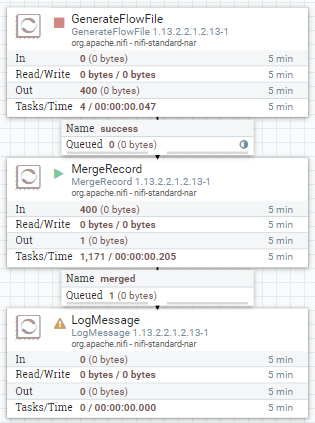
결과적으로 MergeRecord는 각 노드로 들어온 flowfile들끼리만 merge를 하는 것으로 보이며, 여러 노드에서 생성된 flowfile을 하나의 flowfile로 병합하기 위해서는 connection Load Balance Strategy를 Single node로 설정해야함.
결론
- MergeRecord의 병합 우선순위는 다음과 같은 것으로 파악된다.
- Minimum Number of Records의 값이 최우선적으로 적용된다.
- Maximum Number of Records의 값이 그 다음으로 적용된다.
- Max Bin Age의 값이 마지막으로 적용된다.
- Minimum Number of Records이 충족되면 곧바로 merge가 진행되고, Minimum Number of Records가 충족되지 않고 Max Bin Age를 초과하면 merge가 진행된다.
- Maximum Number of Records가 1000일 때 2000 row의 flowfile이 들어오면 flowfile을 1000 row씩 split하지 않고 그냥 2000 row를 다음 프로세서로 보낸다.
- queue가 여러 노드에 분산되면 하나의 flowfile로 merge되지 못하기에 반드시 하나로 merge해야한다면 single node로 queue를 보내야한다.
'NIFI' 카테고리의 다른 글
| cloudera manager에 nifi cfm 2.1.2 서비스 추가하는 방법 (0) | 2022.03.21 |
|---|---|
| nifi updaterecord로 oracle nvl, ms coalesce 함수 사용하기 (0) | 2022.03.04 |
| nifi invokehttp로 ssl 적용된 https 페이지에서 데이터 가져오기 (0) | 2022.03.01 |
| nifi template (0) | 2022.02.27 |
| NIFI QUEUE MONITORING (use controller service) (0) | 2022.02.26 |



댓글