PySpark를 사용한 워드 카운트(Word Count) 알고리즘의 구현과 동작 원리를 분석한다.
전체 코드
import pyspark
test_file = "hello.txt"
sc = pyspark.SparkContext.getOrCreate()
text_file = sc.textFile(test_file)
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print(counts.collect())hello.txt 파일
hello world
hello world
hello
1. SparkContext 생성 및 데이터 로드
import pyspark
test_file = "sample/hello.txt"
sc = pyspark.SparkContext.getOrCreate()
text_file = sc.textFile(test_file)
- SparkContext: Spark 애플리케이션의 진입점으로, 클러스터와의 연결을 설정한다.
- textFile(): 지정된 경로의 텍스트 파일을 읽어 RDD(Resilient Distributed Dataset)를 생성한다.
RDD에는 다음과 같이 저장된다.
2. flatMap 변환
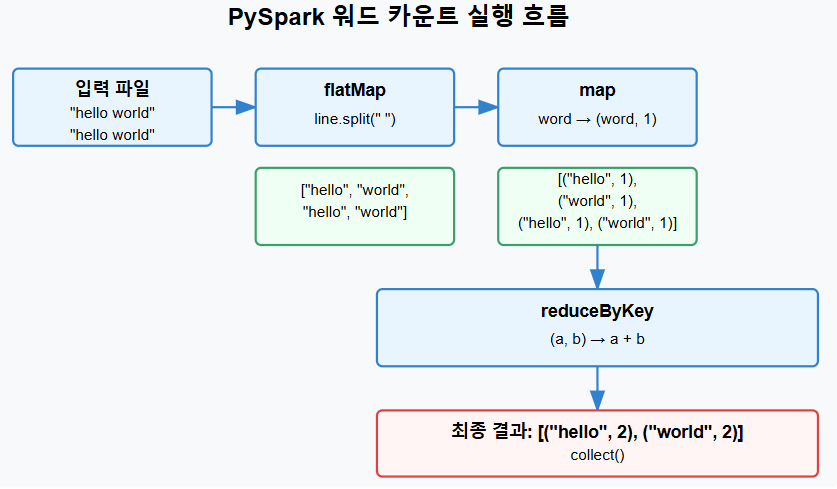
텍스트 파일의 각 라인을 공백으로 분리하여 단어 배열로 변환한다.
counts = text_file.flatMap(lambda line: line.split(" "))
- flatMap(): 각 입력 요소에 함수를 적용하고, 결과를 평면화한다.
- line.split(" "): 각 줄을 공백(" ")으로 분리하여 단어 배열로 변환한다.
flatMap 함수의 동작 과정

다음과 같이 변환된다.

3. map 변환
각 단어를 (단어, 1) 형태의 키-값 쌍으로 변환한다.
text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).collect()
- map(): RDD의 각 요소에 지정된 함수를 적용하여 새로운 RDD를 생성한다.
- lambda word: (word, 1): 각 단어를 (단어, 1) 형태의 튜플로 변환한다.
map 함수의 동작 과정
다음과 같이 변환된다.

4. reduceByKey 변환
같은 키(단어)를 가진 값들을 합산한다.
text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).collect()
- reduceByKey(): 같은 키를 가진 값들에 리듀스 함수를 적용하여 결과를 집계한다.
- lambda a, b: a + b: 같은 키에 대한 두 값을 더하는 연산을 수행한다.
reduceByKey 함수의 동작 과정
다음과 같이 변환된다.

5. 결과 확인
print(counts.collect())

- collect(): RDD의 모든 요소를 드라이버 프로그램으로 가져온다.
- 이 함수는 Action 연산으로, 이전의 모든 Transformation 연산을 실행한다.
결과는 아래와 같다.
워드 카운트의 실행 흐름은 아래와 같다.
'pyspark' 카테고리의 다른 글
| pyspark aggregateByKey (0) | 2025.03.03 |
|---|---|
| PySpark Key-Value 쌍 연산 (0) | 2025.03.01 |
| PySpark의 map과 flatMap 함수 비교 (0) | 2025.02.28 |
| pyspark countByValue (0) | 2025.02.28 |
댓글