1. Data-aware scheduling 개요
- 데이터 셋 업데이트를 기반으로 DAG를 스케줄링할 수 있는 기능이다.
- 아래와 같이 Denpendency Graph를 통해 데이터 셋을 업데이트하는 DAG와 데이터 셋 변경에 의해 트리거된 DAG를 시각적으로 확인할 수 있다.
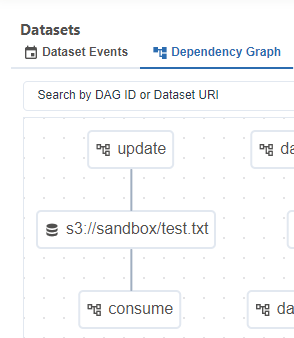
2. Dataset 개념
- 데이터 업데이트를 알리고 이를 기반으로 워크플로우를 트리거하는 역할을 한다.
- 데이터의 논리적 그룹을 나타내는 추상적인 개념으로 실제 데이터를 저장하거나, 관리하지 않는다.
- URI(Uniform Resource Identifier)로 정의된다. 이 URI는 데이터의 위치나 식별자 역할을 하지만, 실제 데이터를 포함하지는 않는다.
3. Dataset 사용 방법
3-1. Dataset 생성 방법
from airflow.datasets import Dataset
example_dataset = Dataset("s3://sandbox/test.txt")
3-2. upstream task에서 Dataset 업데이트
outlets에 Dataset의 이름을 추가하면 해당 task는 Dataset을 업데이트하는 task가 되고, 해당 task가 완료되면, airflow는 Dataset이 업데이트 되었다고 간주하고, 이를 스케줄 조건으로 사용하는 DAG를 트리거한다.
실제 데이터 업데이트 로직은 task 내에서 직접 구현해야 하며, outlets에 Dataset을 추가하는 것은 실제 데이터의 변경과는 직접적인 관련이 없다.
즉 업데이트 로직 없이, outlets에 Dataset이 지정되기만 해도 task 종료 시 Dataset이 업데이트 된 것으로 간주한다.
import pendulum
from airflow.decorators import dag, task
from airflow.datasets import Dataset
example_dataset = Dataset("s3://sandbox/test.txt")
@dag(
schedule="@once",
start_date=pendulum.datetime(2024, 8, 10, 3, tz=pendulum.timezone("Asia/Seoul")),
catchup=False,
tags=["example", "dataAware"],
)
def update():
@task(outlets=[example_dataset])
def update_dataset():
## dataset을 업데이트 하는 로직
print("test.txt")
update_dataset()
update()
3-3. downstream DAG에서 Dataset 업데이트를 스케줄 조건으로 사용
@dag(
schedule=[example_dataset],
start_date=pendulum.datetime(2024, 8, 10, 3, tz=pendulum.timezone("Asia/Seoul")),
catchup=False,
tags=["example", "dataAware"],
)
def consume():
@task
def consume_data():
## 데이터를 consume하는 로직
print("read test.txt")
consume_data()
consume()
3-4. 다중 데이터 셋 사용
아래와 같이 여러 데이터 셋을 스케줄 조건으로 사용할 수 있으며, DAG는 모든 데이터셋이 최소 한 번 업데이트된 후에 스케줄된다.
모든 데이터 셋이 업데이트 되기 전에 한 데이터 셋이 여러 번 업데이트 되는 경우 downstream DAG는 아래 그림과 같이 실행된다.

@dag(
schedule=[example_dataset, example_dataset2, example_dataset3],
start_date=pendulum.datetime(2024, 8, 10, 3, tz=pendulum.timezone("Asia/Seoul")),
catchup=False,
tags=["example", "dataAware"],
)
def consume():
@task
def consume_data():
print("read file")
consume_data()
consume()
4. 조건부 표현식을 사용한 스케줄링
airflow는 데이터 셋 조건을 결합하기 위한 두 가지 논리 연산자를 지원한다.
- AND (`&`) : 지정된 모든 데이터 셋이 업데이트된 후 downstream DAG가 트리거 된다.
- OR (`|`) : 지정된 데이터 셋 중 하나라도 업데이트 되면 downstream DAG가 트리거 된다.
@dag(schedule=(example_dataset & example_dataset2) | example_dataset3)
def complex_scheduling_dag():
pass
5. 시간 기반 스케줄과 데이터 셋 기반 스케줄 결합
DatasetOrTimeSchedule을 사용하면 시간 기반 스케줄과 데이터 셋 기반 스케줄을 결합해 사용할 수 있다.
지정된 cron 표현식과 데이터 셋 업데이트 두 조건 중 하나라도 충족되면 DAG가 실행된다.
from airflow.timetables.trigger import CronTriggerTimetable
from airflow.timetables.datasets import DatasetOrTimeSchedule
from airflow.decorators import dag, task
import pendulum
@dag(
schedule=DatasetOrTimeSchedule(timetable=CronTriggerTimetable(cron='45 4 * * *', timezone="Asia/Seoul"), datasets=[example_dataset]),
start_date=pendulum.datetime(2024, 8, 10, 3, tz=pendulum.timezone("Asia/Seoul")),
catchup=False,
tags=["example", "dataAware"],
)
def consume():
@task
def consume_data():
print("read file")
consume_data()
consume()
데이터 셋 업데이트로 실행된 DAG는 dataset_triggered, cron 표현식에 의해 실행된 DAG는 scheduled로 표시된다.


'aiflow' 카테고리의 다른 글
| airflow Variable (0) | 2024.09.02 |
|---|---|
| airflow Dynamic Task Mapping (0) | 2024.08.20 |
| airflow Params (0) | 2024.08.17 |
| airflow 외부 시스템 이용하기 -2: ImpalaHook, S3Hook (0) | 2024.08.17 |
| airflow 외부 시스템 이용하기 -1 : DockerOperator, KubernetesPodOperator, SparkKubernetesOperator(SKO) (0) | 2024.08.17 |




댓글